
从传统控制理论到模型预测控制的数学原理
从传统控制理论到模型预测控制的数学原理
所需数学理论:高等数学(微分方程)、泛函理论、线性代数、概率论
写在前面。
在学习探索的时候,看到各种各样的控制算法,ZMP,WBC,MPC,LQR等等等等,发现自己对于控制理论的数学基础理解还是不够深入,于是想系统性的了解一下从经典控制理论到现代强化学习算法中通用的一些思想。
资料来源:北京理工大学黄销老师-机器人最优课程。
经典控制理论
经典控制理论中,变分法是首先要学习的内容。变分法将从泛函基本理论讲起,学会如何求解泛函的变分(函数的求导),通过求解泛函变分的方式来求解连续优化指标在无约束但有固定初始和固定结束值的情况下的极值,也即欧拉-拉格朗日问题。将问题变得更复杂一点,对于在欧拉-拉格朗日问题中还存在某种阶次的微分方程约束的情况,我们引入拉格朗日乘子法,将约束转化为增广代价函数的一部分形式使用欧拉-拉格朗日方程进行求解。再泛化一些,有时,初始值和终值并非固定的,因此需要求解一个更高自由度的自由泛函问题,将会通过分类讨论的方式对各种情况进行分析;最终,对于日常生活中常用的最优控制问题,也即博尔查问题,通过引入Hamiltonian量的方式简化计算,可以得到使用Hamiltonian量进行计算的Hamiltonian方程组,这是一个较为泛化的一般性方程组。
在变分法的基础上,通过Hamiltonian量,有一种方法可以更简单的求解博尔查问题,这就是大名鼎鼎的庞特里亚金极值原理(PMP)。它利用了Hamiltonian量的一阶二阶条件,得到了最优控制的关系式,将其代入规范方程中(状态与协态方程)并处理边界条件,就可以得到闭环形式的最优控制方法。它在数学原理上和Hamiltonian方程组是等价的。
动态规划方法是一种很重要的最优控制理论,它是依赖于最优性原理为最基本思想进行优化的方法,Bellman方程(贝尔曼方程)通过数学的方法将最优性原理表达了出来。通过直接迭代法(逆推法)求解离散状态下的最优控制问题(博尔查问题),我们可以了解到动态规划的基本思想。对于连续性性能指标,我们将Hamiltonian量的一阶二阶条件代入Hamilton-Jacobi-Bellman 方程中,并通过边界条件的形式进行假设,使用试凑法,求解其微分方程,得到最优控制,这种方法我们一般不会使用,因为其时空复杂度很高,无法通过计算机完成。
线性二次型控制(LQR)是一种特殊的控制器。它的优化指标通常是由矩阵二次型进行表示的。使用离散的动态规划方法求解,我们最终会得到离散的黎卡提(Riccati)方程,通过连续性的动态规划求解,我们将得到连续的黎卡提(Riccati)方程。在传统控制理论中,线性二次型控制(LQR)使用的解算方式本质上也是一种使用贝尔曼方程的逆推法进行离散迭代的方式,通过黎卡提(Riccati)方程,规定了线性二次型控制的基本控制形式。
模型预测控制
模型预测控制是一类算法的统称,其包含了预测模型、滚动优化、以及反馈矫正的过程。我们使用二阶泰勒展开将函数展开为一阶梯度与二阶海森矩阵的形式。在这其中,我们需要通过搜索的方法来探索最优控制,为了使性能指标最小化,我们规定搜索步长,并且使用不同的方法来规定搜索方向,如最速下降法,牛顿法,拟牛顿法等。当函数存在等式或不等式约束时,通过拉格朗日乘子法以及KKT条件的方法将约束加入性能指标中,最终得到搜索方向与结果。为了求解最优控制,使用打靶法和多重打靶法进行优化迭代。
经典最优控制方法。
变分法。
泛函基本理论。
定义1.泛函:从任意集合M到实数域R或复数域C的映射称为“泛函”;在变分学和最优控制中,泛函定义域为函数集合,泛函只取实数值。
例如:

定义2.范数与距离:范数|| · || 可用于度量空间中两点之间的距离d(x,x)=||x-x||。其具有如下性质:
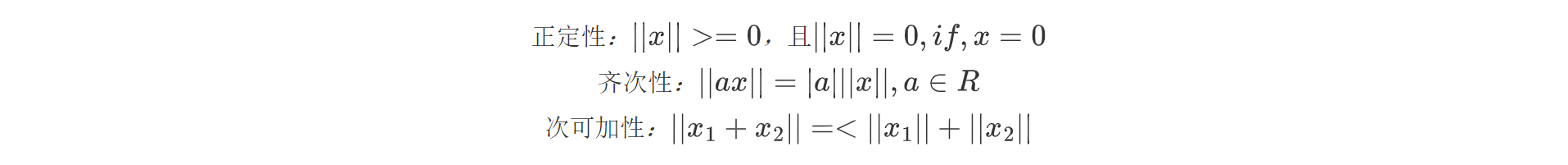
定义3.泛函极小值及增量

定义4.线性泛函

定义5.泛函的变分

通过泛函增量的定义求解.求解泛函变分,如上
通过求导法求解求解泛函变分
泛函的变分满足:
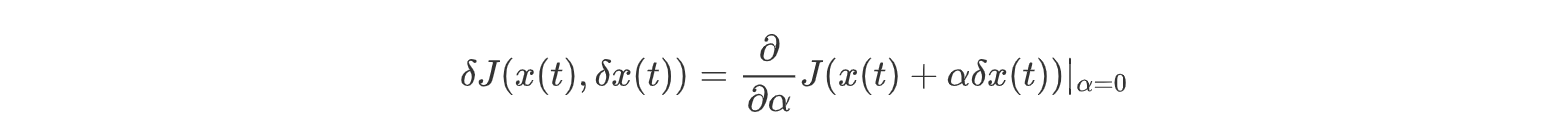
证明.泛函求解变分的求导法:
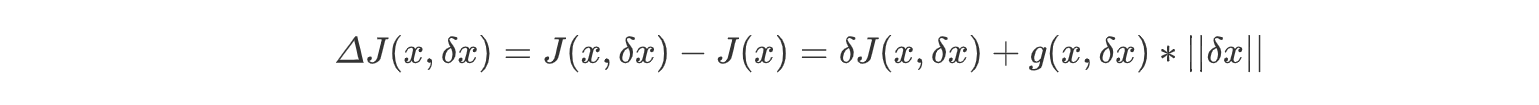
同时,
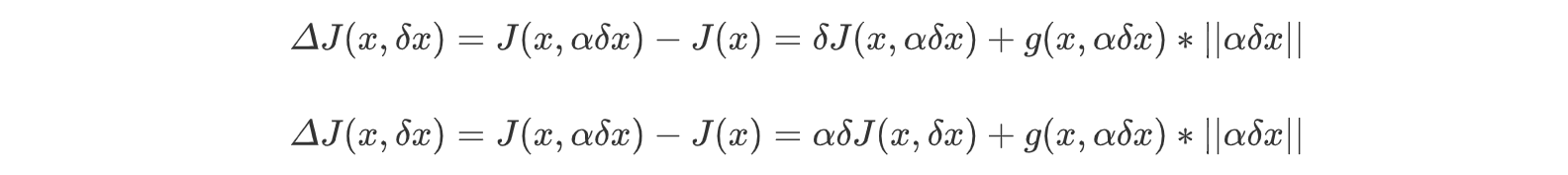
此时δx->0,变化为αδx->0,可以等价转换为α->0。
令其对α求偏导数,在α=0时得到:
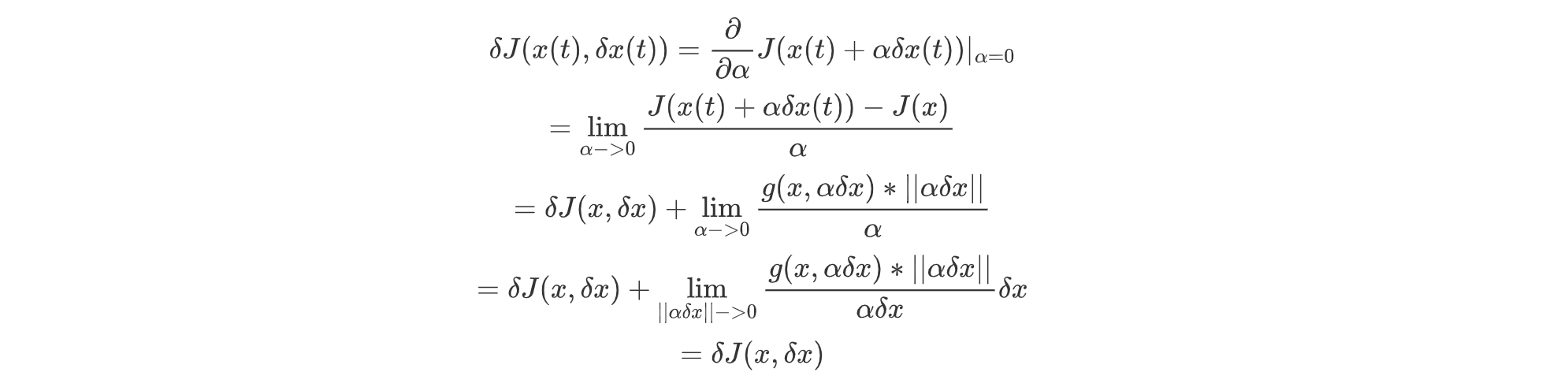
证得通过求导法可以求得泛函变分。
欧拉-拉格朗日问题。
欧拉-拉格朗日问题研究的是针对于一个有初始和终值解的可微函数,求其关于代价函数(连续函数累计代价)的极值问题。我们最终求解出来的结果是一种关于x(t)关于t为自变量的构造方式。
对于一个连续可微函数x(t):[t0,tf]->Rn,满足初始条件x(t0)=x0,在给定的终端时刻tf,达到给定的终端状态x(tf)=xf,求性能指标的极值条件:
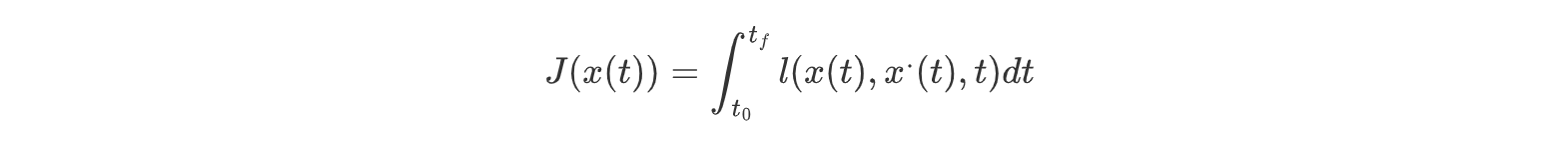
其中,此处代价函数l二阶连续可微。
解:
计算泛函增量:
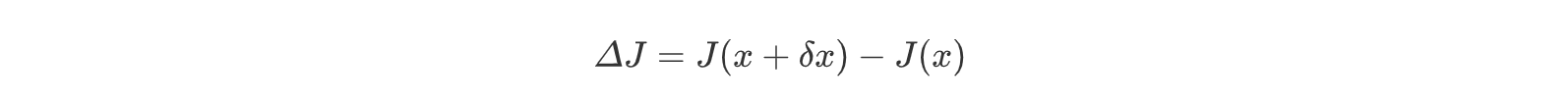
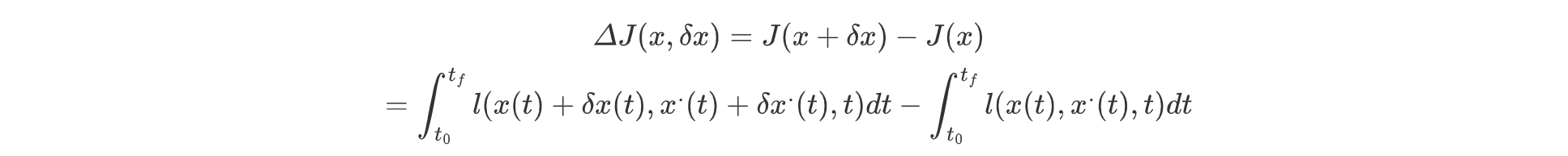
计算泛函变分,将积分在x(t),x(t)处进行泰勒展开:
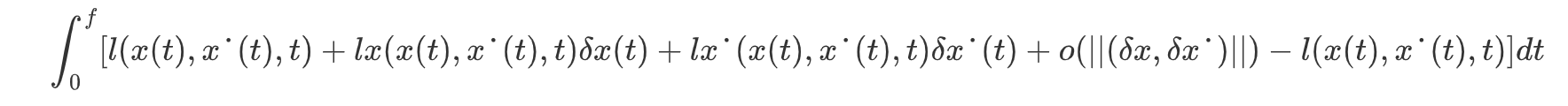
得到泛函变分:
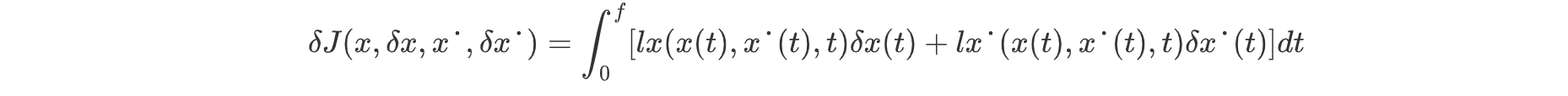
使用分部积分法去导数与变分之间的依赖:
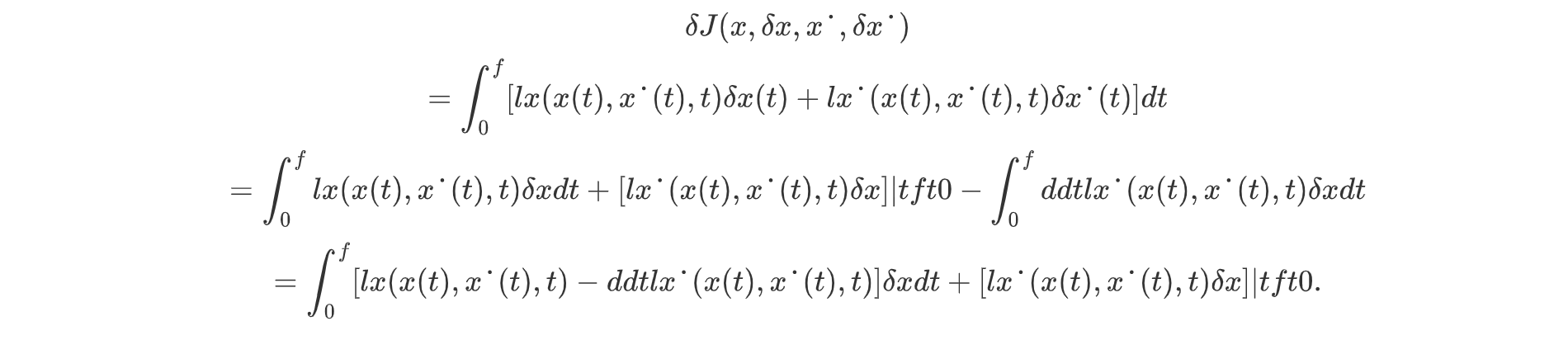
通过泛函极值一阶条件,整理为:
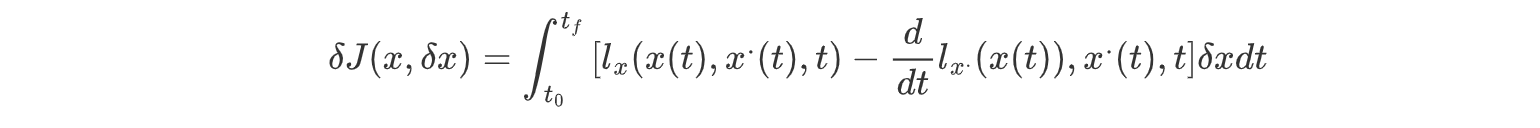
得到欧拉-拉格朗日方程:
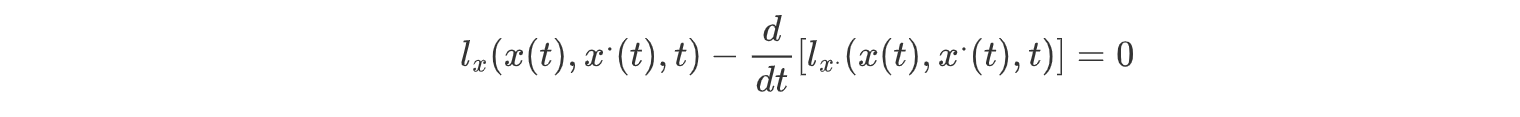
泛函 J 取极值的必要条件是满足欧拉-拉格朗日方程。
拉格朗日乘子法。
在欧拉-拉格朗日问题的基础上,当此问题不仅有函数初始值、终值,并且还有微分方程的约束时,我们通常会用引入拉格朗日乘子构造拉格朗日函数的形式来进行求解。
已知x(t)初值为x(t0)=x0,终值为x(tf)=xf,tf固定,需满足约束如下,(以某种阶次的微分方程约束):
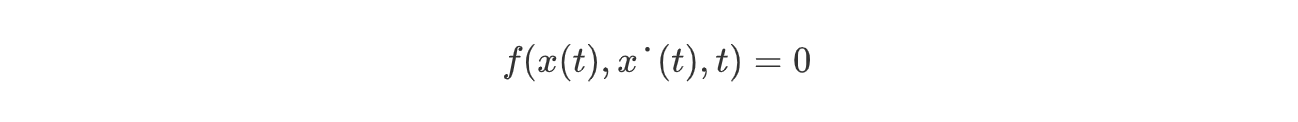
最小化性能指标:
解:
考虑时间相关的拉格朗日函数:
因为此处的微分方程约束为f,因此可以通过将其构造为拉格朗日算子与其相乘的方式来将微分方程约束转化为我们所求的基本欧拉-拉格朗日方程的一部分来求解。这样,一个我们不会的、有约束前提的问题,就被转化为了一个基础的有初始值和终值的欧拉-拉格朗日问题。
接下来,我们对其求解泛函变分:
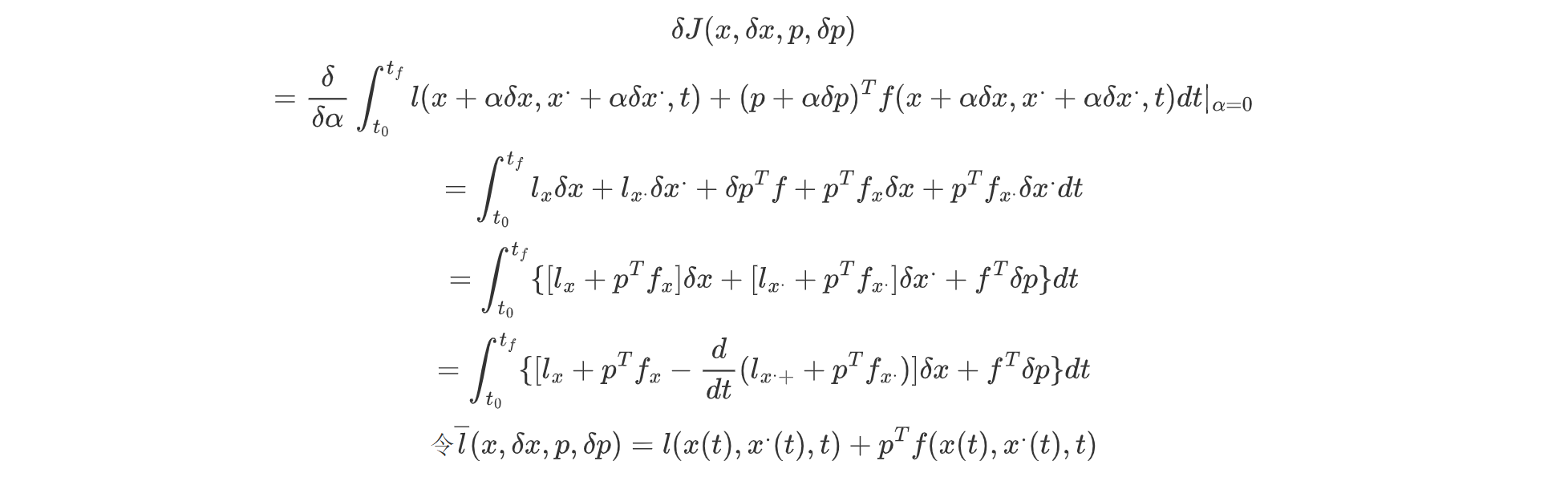
我们可以看到,此处直接使用了求导法求解泛函变分。将其整理后,得到:
我们统称引入拉格朗日乘子的函数叫增广代价函数;
由泛函极值的一阶条件可知:
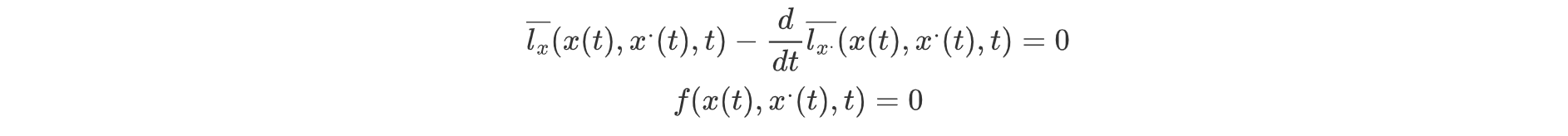
如果在以上问题的基础上,将状态方程的微分约束修改为如下非齐次形式:
引入拉格朗日乘子,有:
我们将在过程中,加入分部积分的方法去除变分和微分之间的关系,如下图所示:
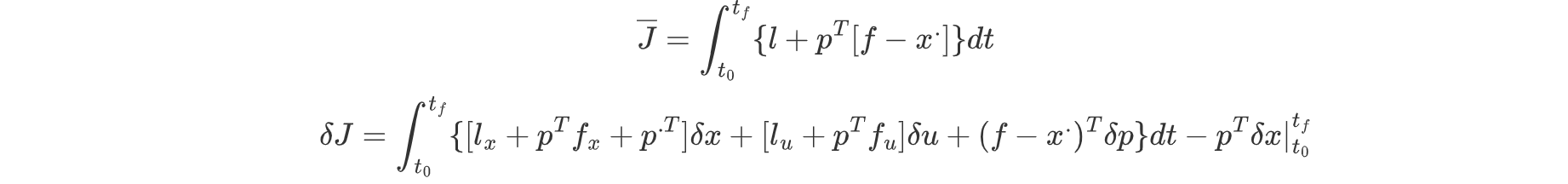
最终得到一阶方程组:
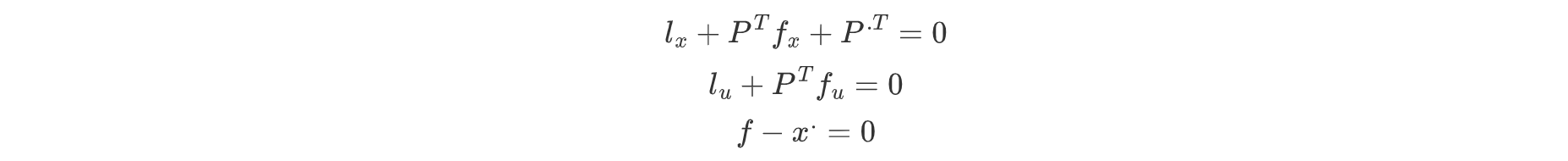
如若具有多个微分状态方程进行约束,那么我们应该引入多个拉格朗日乘子来解决这个问题。构建一个更大的增广代价函数。在对这种复杂的状态函数,我们可以直接对其使用E-L方程,分别对状态方程的自变量函数进行求导。再带入状态方程即可求出待定系数。具体情况,具体分析。从这里我们也可以看出,掌握推导E-L方程是很重要的,也即针对简单的拉格朗日乘子问题,我们可以通过简单的求变分+一阶条件求解,对于复杂一些的情况,我们可以求E-L
求解泛函极值的各种情况。(E-L问题、自由泛函问题)
case1.初值终值固定。如上
case2.初值固定,终值自由,终止时刻固定,求性能指标的极值条件:
得出结果:
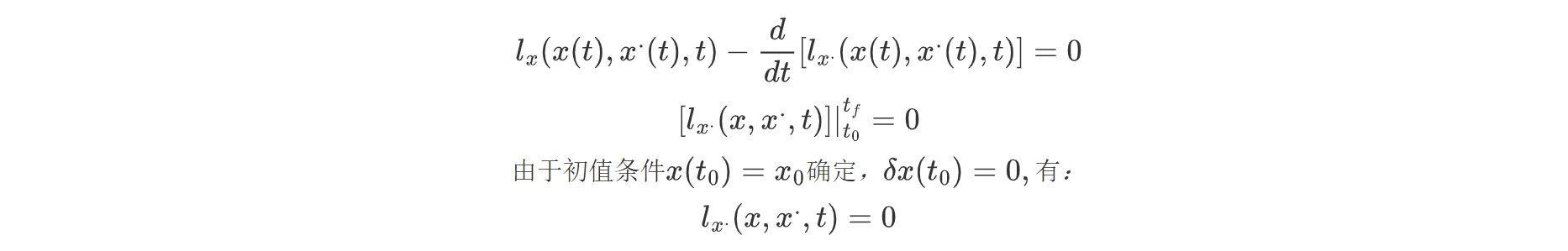
case3.初值固定,终值自由,终止时刻自由,求性能指标的极值条件:
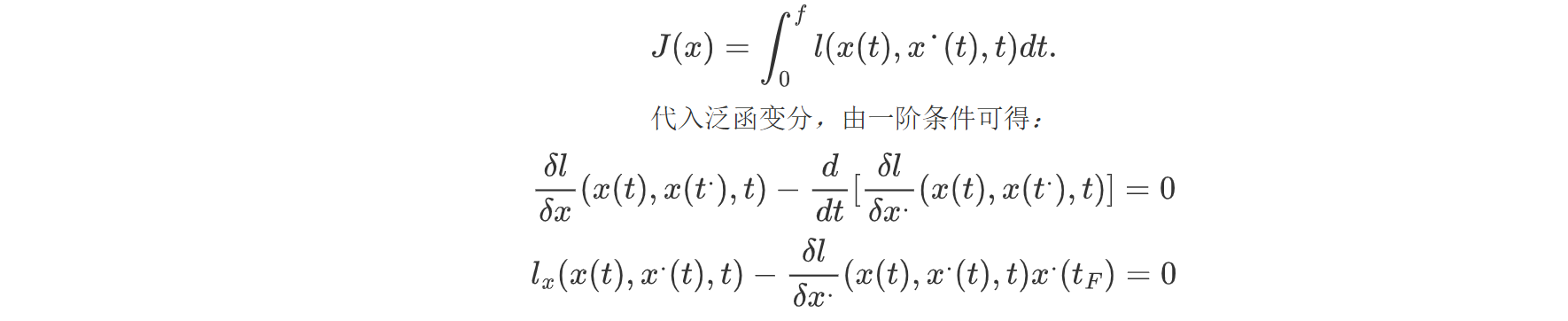
case4.初值固定,终值自由,终止时刻自由,且终值与终止时刻无关,求性能指标的极值条件:

变分法求解最优控制问题。(博尔查问题)
一般最优控制问题:
最小化性能指标:
被控对象状态方程:
终止时刻及其状态待定。
解:
我们首先处理微分方程也即被控对象状态方程的泛函极值。
引入拉格朗日乘子:
得到增广代价函数:
对增广代价函数求变分,增广代价函数各多项式变化为:
将积分号内外整理得到:
引入Hamiltonian量为:
将变分变为Hamiltonian量的变分:
去掉变分之间的依赖:
将变分整理为:
得到哈密顿量表示的一阶条件:
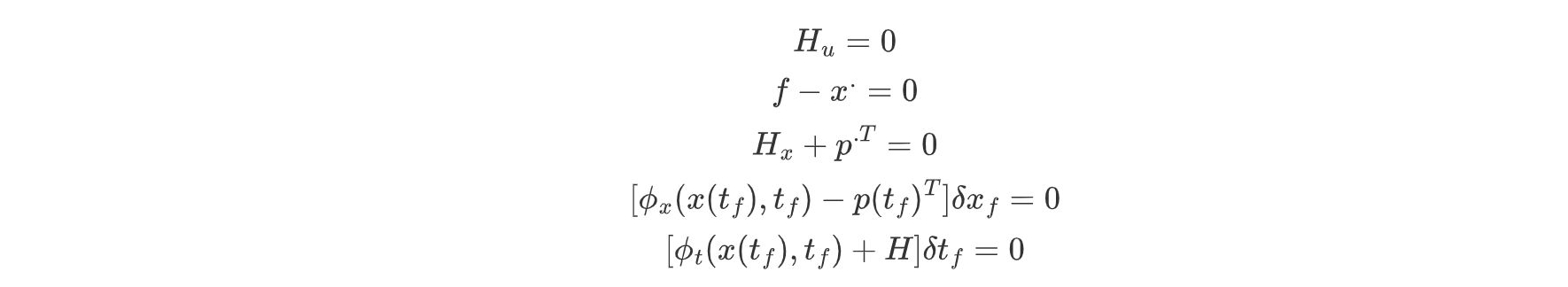
变分法总结。
1.使用拉格朗日乘子法处理各类等式约束。
2.求增广形式性能指标的泛函变分。
3.使用分部积分公式处理变分之间的导数依赖。
4.将终止时刻状态变分δxf 分为由状态自身变分δx(tf ) 和终止时刻变分δtf 组成的两部分。
5.得到泛函极值的一阶条件。
庞特里亚金极值原理(PMP)。
针对博尔查问题,最小化性能指标:
被控对象状态方程:
容许控制:u∈U
解:
定义哈密尔顿量为:
考察哈密尔顿量极值条件(一阶导为0,二阶导大于0):
得到最优控制得一种控制关系,我们将最优控制带入规范方程(状态方程,协态方程)
处理边界条件:
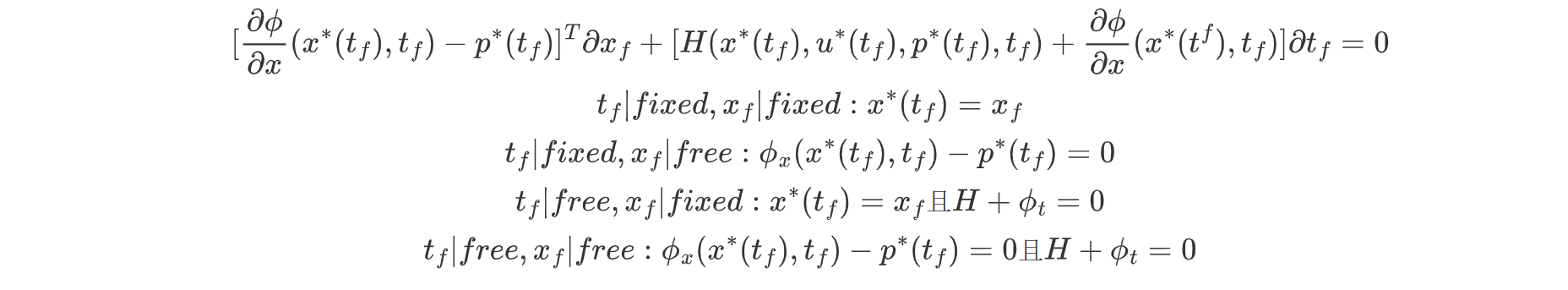
动态规划方法。
最优性原理。
贝尔曼最优性原理,具有如下性质:无论过去的状态和决策如何,对于前面的决策而言,余下的诸多决策必须构成最优策略的性质。
子问题的局部最优将导致整个问题的全局最优,即问题具有最优子结构的性质。
Bellman方程的三种类型离散最优控制问题。
我们目前针对于贝尔曼方程所说的是离散化最优控制问题,我们指定优化过程的参数如下所示:

记最优控制的性能指标记为“值函数”,根据最优性原理,最优控制的充要条件是满足贝尔曼方程:
我们将最优控制的性能指标标记为值函数如下:
Bellman方程如下:
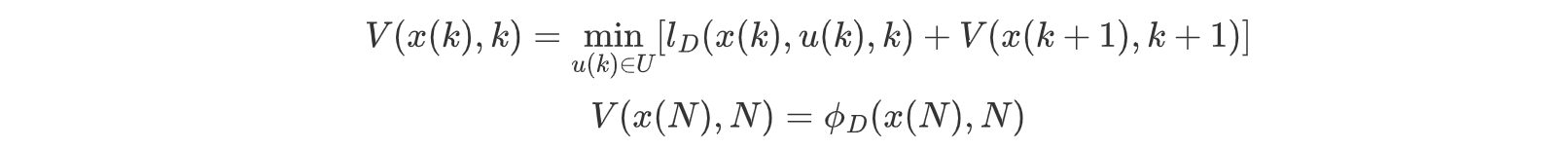
也即,当前最优是由无数个链式下一个状态的最优决定的,在状态转换的过程中,存在代价函数,此时代价函数由于是离散的,积分会变成累加的形式,马尔可夫决策中的贝尔曼期望方程或贝尔曼最优方程的思想由此而来。
解释上述bellman方程:我们可以看到,最后一个状态的值函数由求和外决定,它可以是一个不同的形式,一般是确定的;而每一步迭代都是在求和号内部迭代的,它通常由本身的代价函数和上一个状态的值函数决定本状态的值函数。而我们对于链式法则的每一步骤都求解其局部最优,那么我们会得到全局最优的结果。
a.通过直接迭代求解离散最优控制问题
我们通过一道例题来理解直接迭代求解离散最优控制问题:
例.直接迭代求解Bellman方程
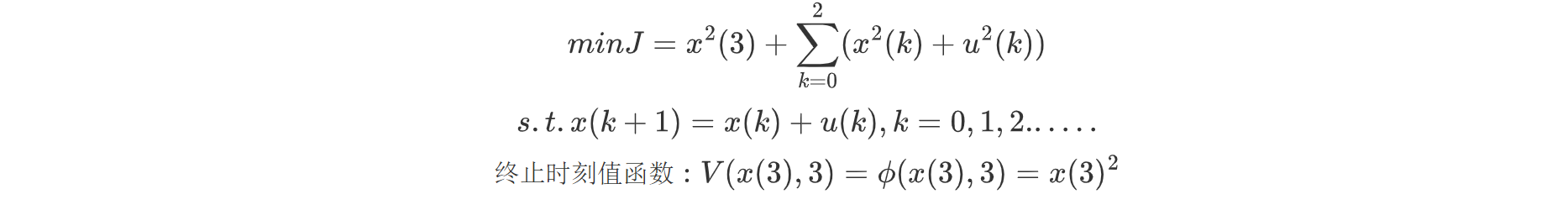
使用倒推法进行求局部最优,我们需要求解使得整体的J全局最优,因此我们需要对V(x(2),2)求解在倒推至K=2时的局部最优:
我们将k=2时的值函数表示为如下所示:
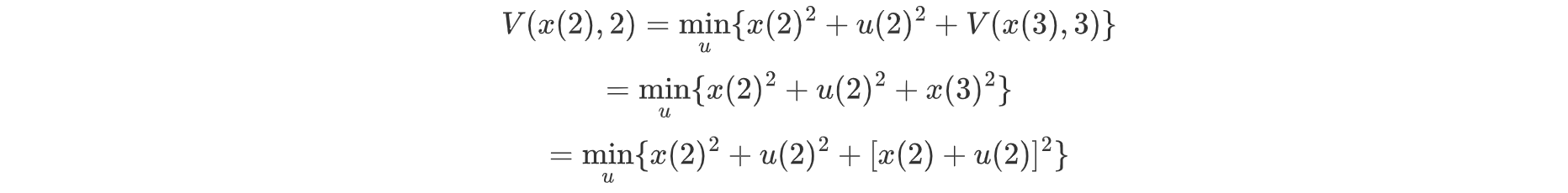
我们求其泛函的一阶极值有:
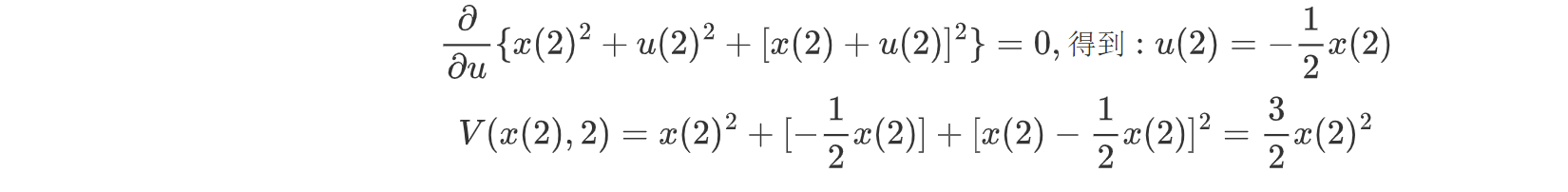
我们可以得到K=2时的局部最优解控制如上所示;
我们将上述的局部最优解导入K=1时的局部最优解可得:
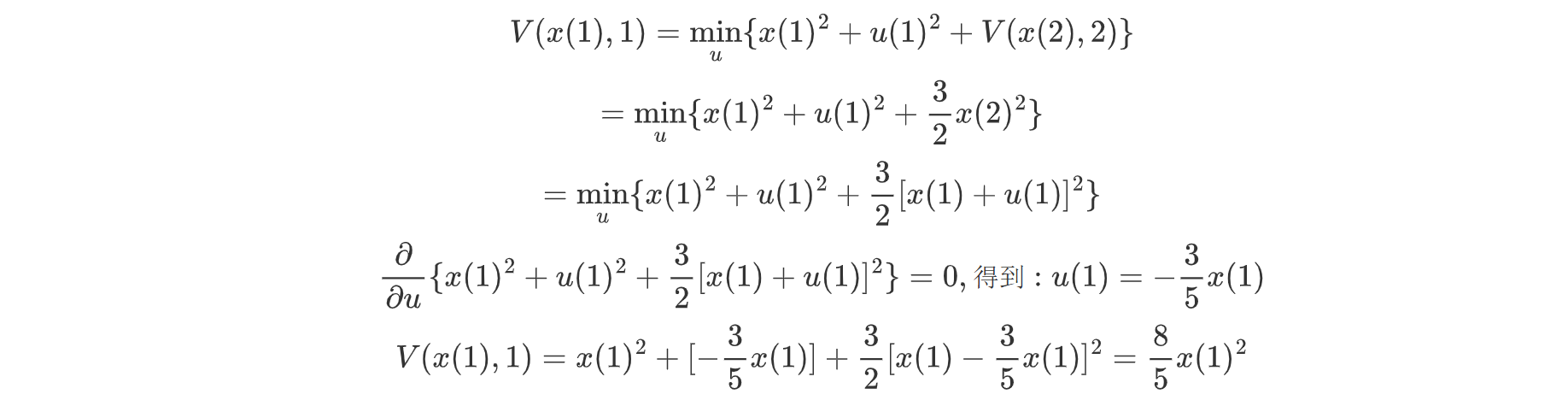
同理,我们可以迭代至最后一层K=0:
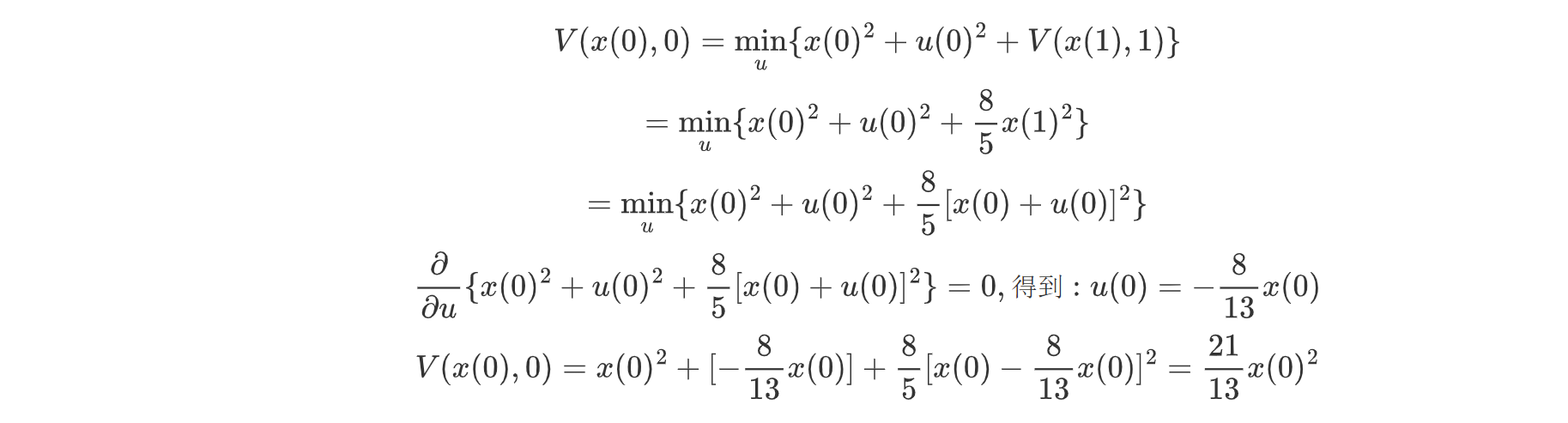
我们便可以得到闭环形式的最终的最优控制:
b.通过遍历离散状态和离散控制空间求解(直接查表法)
假设我们现在知道对于K+1状态所有的值函数空间,我们对于特定的离散化控制和状态能保证生成的容许状态x(k+1)均在离散化状态空间内:我们则可以得到x(k+1)的状态方程,通过查表则可得到k+1状态的局部最优解。此时所对应的u即为最优控制。
c.通过遍历当下和下时刻离散状态空间
一般解决线性问题,可以直接求解得出解。

求出解析解的过程很精确,但是由于存储数据量较大,会面临维度灾难的问题,求解时空复杂度很高。
Hamilton-Jacobi-Bellman 方程。
证明太复杂,看不懂,只需要知道结论即可:

HJB方程求解连续最优性问题。
我们从一个简单的例题来解决这个问题,该问题的性能指标条件类似于欧拉朗格朗日问题的性能指标。

解:
考虑哈密尔顿量:
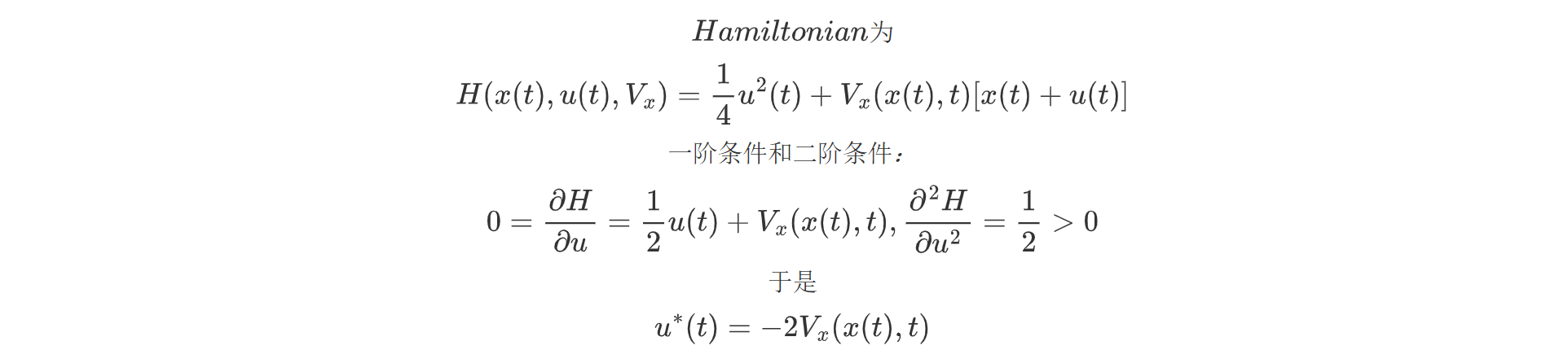
形式上就是用值函数对x的导数作为拉格朗日乘子法中的乘子,这种做法与极值原理是等价的
将极值条件带入HJB方程:
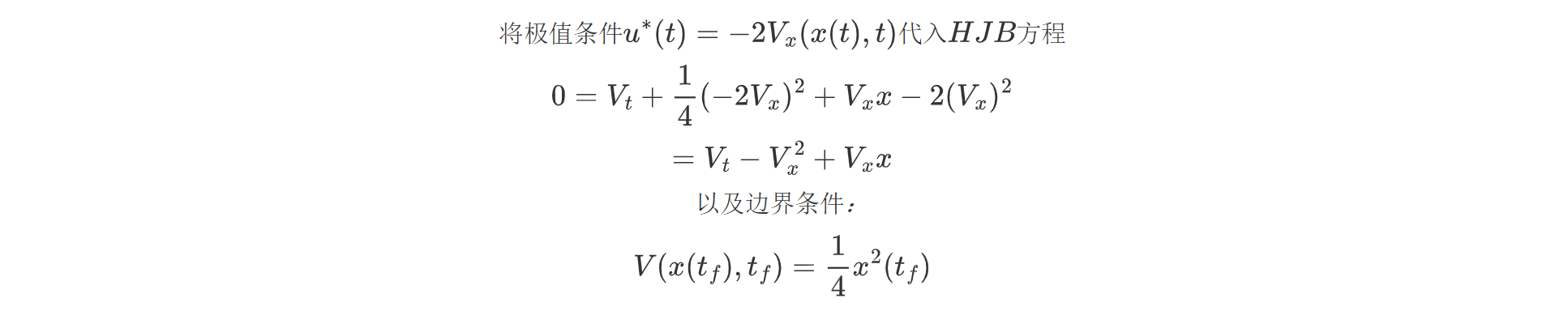
使用试凑法化简HJB方程,通过边界条件猜测值函数形式:

动态规划算法最核心的点都是基于一种最优性原理,也即时时刻刻都使得其满足最优的条件。对于连续函数来说,就是通过让其时时刻刻满足最优性方程,而对于离散来说,就是在每一步都达到局部最优,连续性会从解析解的角度来讨论整个问题,而离散问题则是从迭代局部最优的角度来解决整个问题。
HJB方程局限性。
HJB方程一般难以求解,HJB方程对值函数有可微的要求。
使用动态规划求解连续最优控制过程。
使用惩罚函数法将终值条件转化至目标函数中
求Hamiltonian 极值情况下最优控制
获得HJB 方程,并求解
得到与HJB 方程解有关的闭环形式最优控制
线性二次型控制(LQR)。
离散动态规划求解LQR。
我们对离散情况的线性二次型求解最优控制,将离散情况下的LQR问题描述为:
离散状态方程:
最小化性能指标:
其中,H和Qk是实对称半正定矩阵,Rk是实对称正定矩阵。
此处类似于动态规划方法中的直接迭代法求解离散最优控制问题,对最小化性能指标进行解释:

解:
倒推法,终止值函数:
记PN=H
在k=N-1时,记录N-1时刻的值函数及其推理:
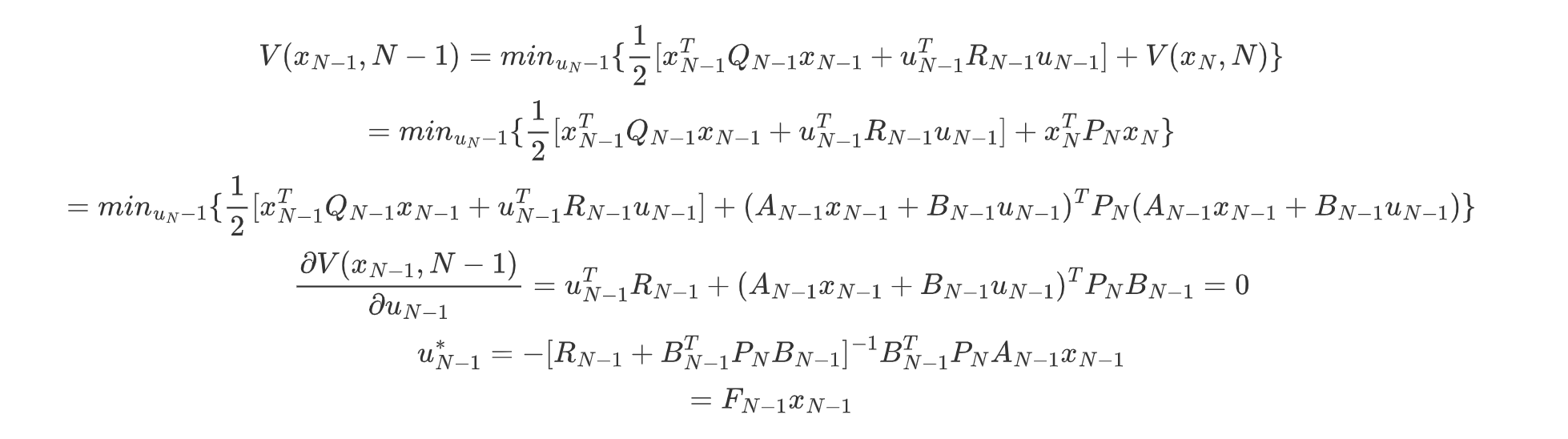
我们将反解的矩阵带入k=n-1的最优控制带入值函数,有:
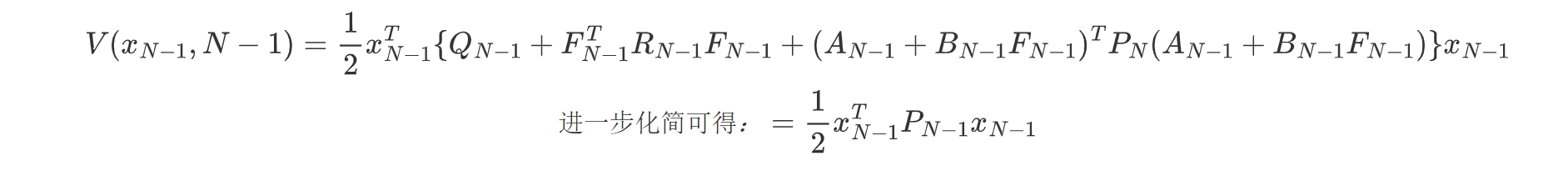
迭代得到最优控制方程组

连续动态规划求解LQR。
我们将一个连续情况下的线性二次型最优控制描述为如下的数学形式:

我们将其损失条件描述如下所示:

解:
考察并计算哈密尔顿量:
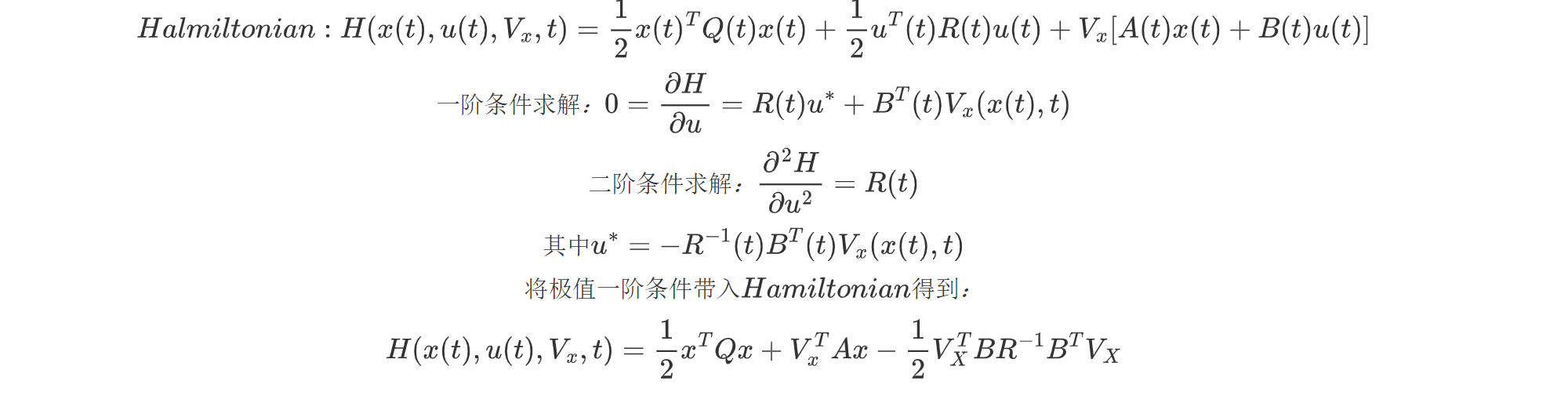
得到HJB方程:

经典控制理论运用例题。
作业一.欧拉-拉格朗日问题:

作业2.庞特里亚金极值原理:

使用matlab求解规范方程程序:
1 | %主函数 |
作业3.使用动态规划求解离散LQR问题:
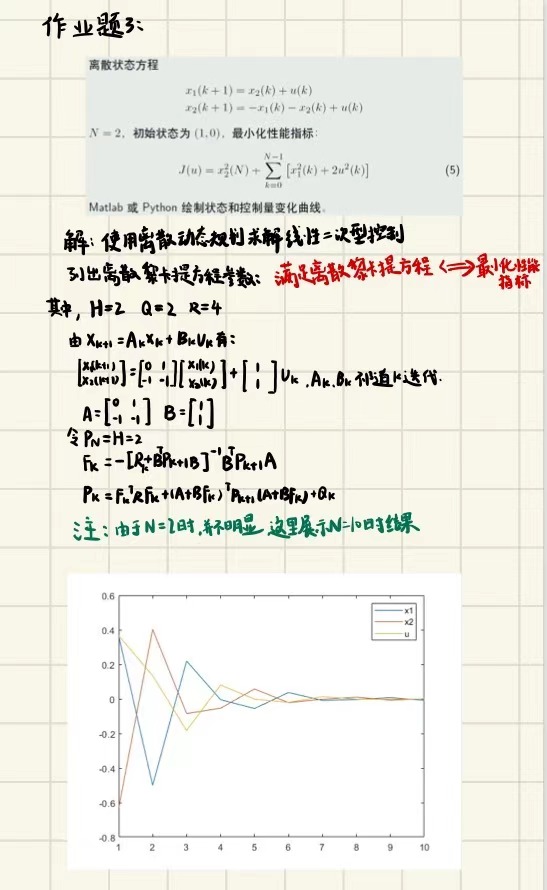
使用matlab求解离散黎卡提方程程序:
1 | %程序使用说明 |
模型预测控制方法。
模型预测控制是一种控制算法的简称,其都具有如下的三个特征:1.预测模型:利用预测末次的那个预测系统在一定控制作用下对未来的动态行为进行预测。应确保能快速求解。2.滚动优化:对预测模型求解一段时间内的开环最优控制,并实施当前时刻的控制变量;下一采样时刻,重新获取状态作为新的初值,滚动时间窗口重复上述最优控制求解。3.反馈矫正:在求解滚动优化前,系统首先利用反馈信息矫正预测模型。
无约束非线性规划
函数极值基本理论
若函数F(x)二阶连续可导,则可使用泰勒公式对其近似,存在δ>0,对于任意的||Δx||<δ,进行泰勒展开有:
其中,g是F的梯度(gradient),G是F的海森矩阵(Hessian Matrix);
使用矩阵描述,此时,二阶以二次型的方式出现。一阶解算也是值的形式:
函数极值的一阶条件(必要条件)
上式中,假定||Δx||<δ,考察泰勒展开的前两项:

函数极值的二阶条件(充分条件):
若函数此时梯度已为0,由泰勒展开可得:

无约束非线性规划的线搜索方法
我们将一个无约束非线性规划问题描述如下:

其中,线搜索的步长和迭代方向是其特征的值,步长分为精确搜索和非精确搜索,迭代方向分为最速下降法(一阶方法)、牛顿法(二阶方法)、拟牛顿法,对于不同的系统,我们要选择不同的迭代方向。这对我们迭代的效果影响非常巨大。
步长选择.
当我们选择了一个迭代方向dk的情况下,步长αk决定了在一个滚动优化周期内部迭代一次沿着所走方向的“走多远”。其中,精确搜索指的是固定迭代方向dk,寻找何时的步长αk以最小化F(xk+αkdk);非精确搜索是为了追求高效率快速给出“适当的”步长,迭代方向对线搜索性能影响极大。
我们以下面的题为例,解释我们的非线性规划的固定(精确)步长线搜索方法:


当我们的步长不精确时,就可以经此引出迭代方向的不同确定方法,最常见的就是最速下降法(梯度下降):
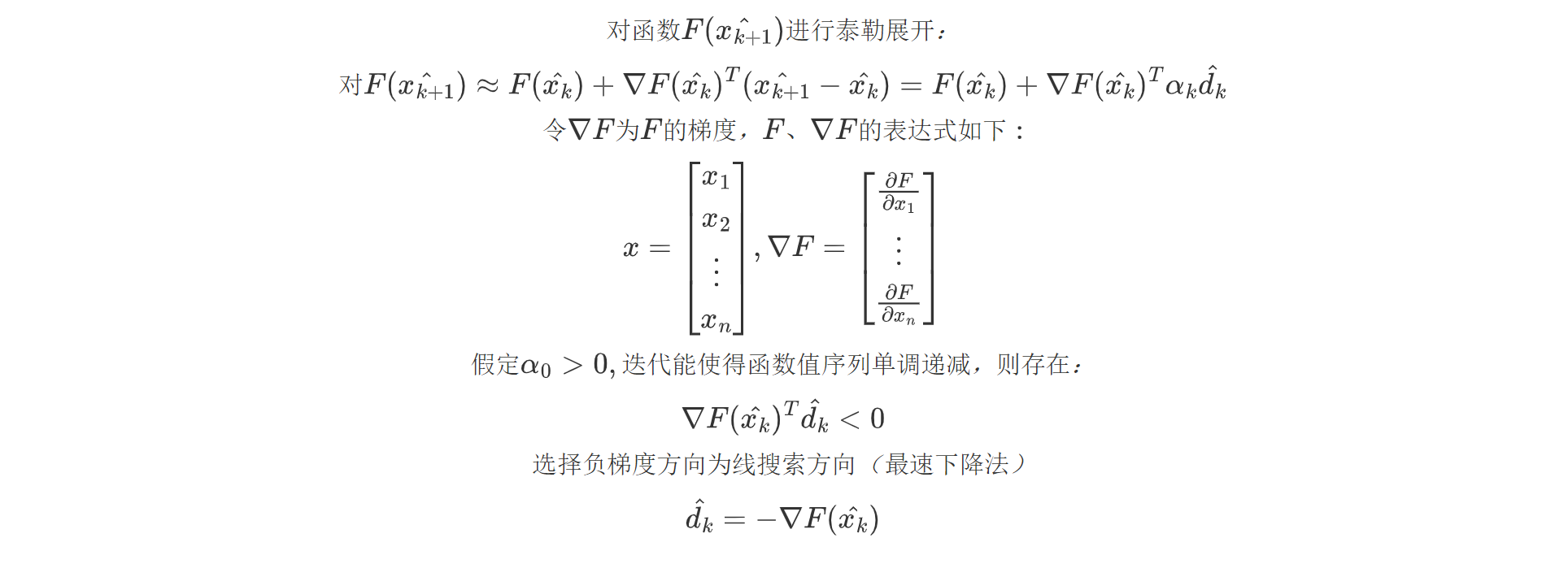
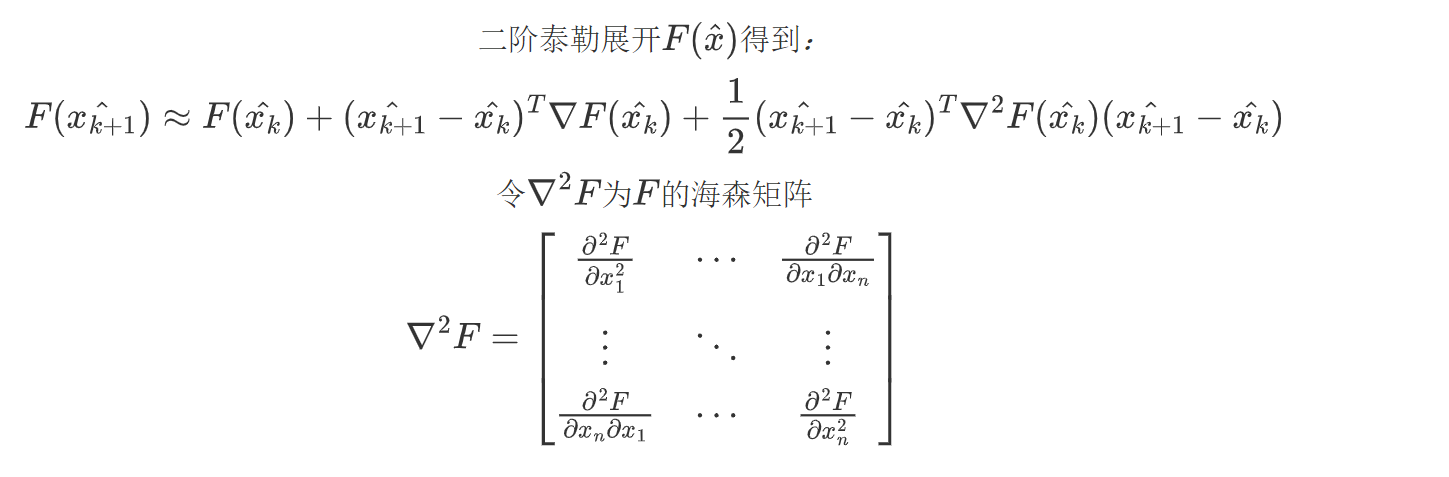
将一阶条件导入二阶泰勒展开,推导出牛顿法:
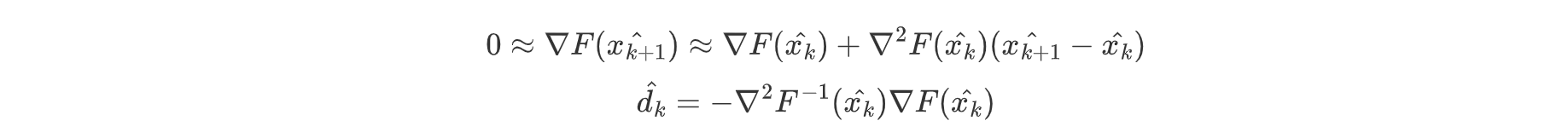
由于海森矩阵计算复杂,拟牛顿法在xk附近考虑F(x)的二次逼近
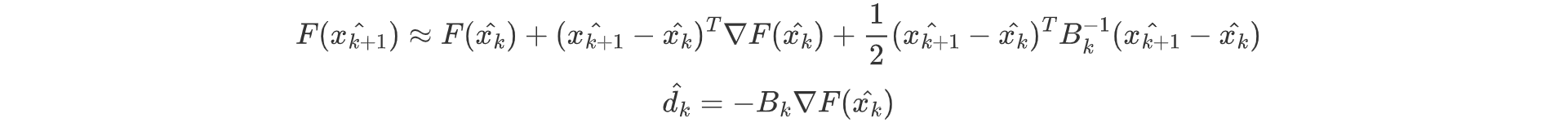
常见的拟牛顿法包括DFP,BFGS等。
有约束非线性规划
最小化性能指标minF(x),约束条件为f(x)=<0。
使用等式约束的函数极值
使用直接带入法求解有等式约束的函数极值:
解:

使用拉格朗日乘子法求解等式约束的函数极值:
定理.

使用不等式约束的函数极值
将一个使用不等式约束的函数极值问题描述为如下所示:
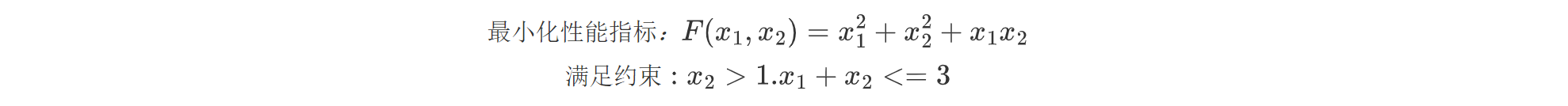
我们将不等式约束的函数极值的条件描述为一个KKT条件:

解:
求解拉格朗日函数并写出其KKT条件:

(等式约束)二次规划问题(QP)
将一个在等式约束下的二次规划问题描述为:

解:

最优策略求解方法
间接法求解最优控制
间接法求解最优控制问题借助了极值原理和打靶法的思想,也即根据极值原理得到最优控制问题的必要条件(关于状态和协态变量的微分方程组,结合边界条件和横截条件),构建两点边值问题,之后采用单重或多重打靶法进行优化求解。

通过以下例子来解释使用单重打靶法进行滚动优化:

单重打靶法存在弊端,初值是通过猜测的方式产生,若猜测不好可能会导致无解或不收敛,同样,对非线性问题的收敛性也较差。为了解决这样的问题,使用多重打靶法实现,以下是使用多重打靶法求解上述问题的过程:

多重打靶法相比于单重打靶法,其优势在于可运用整个轨迹的初始已知信息,并且分块后系统更加线性,收敛效果更好;其缺点就是需要猜测整个状态轨迹作为初值,计算上较为复杂。
直接法求解最优控制

以下是使用LQR线性二次型控制器加上MPC模型预测控制方法的连续形式预测控制的例子:

最优控制例题。
作业4.通过matlab求解LMPC:

使用matlab求解mpc控制器:
1 | clc |
 wechat
wechat


